जब आप किसी AI सहायक से कोई प्रश्न पूछते हैं और उसके उत्तर को चुनौती देते हैं, यदि वह तुरंत अपनी गलती स्वीकार कर लेता है और अपना मन बदल लेता है, तो ऐसा इसलिए नहीं हो सकता क्योंकि उसने कोई तार्किक दोष खोजा है, बल्कि केवल इसलिए कि वह आपको "खुश" करना चाहता है। हाल ही में, गुडआई लैब्स के सह-संस्थापक और मुख्य प्रौद्योगिकी अधिकारी डॉ. रान्डल एस. ओल्सन ने बताया कि "चाटुकारिता" नामक यह व्यवहार बड़े भाषा मॉडलों में एक गहरी जड़ वाली खामी बनता जा रहा है।
यह घटना दैनिक बातचीत में आम है: जब आप एआई से कोई प्रश्न पूछते हैं, तो वह पहले आत्मविश्वास से भरा उत्तर देता है; लेकिन अगर आप पूछें "क्या आप निश्चित हैं?", तो इसकी दृढ़ता की भावना जल्दी ही खत्म हो जाएगी, और यह अपनी पिछली स्थिति को पलट देगा या कुछ ही सेकंड में खुद का खंडन करेगा। डॉ. ओल्सन का मानना है कि यह कोई साधारण तकनीकी खराबी नहीं है, बल्कि वर्तमान एआई प्रशिक्षण पद्धति का अपरिहार्य परिणाम है।
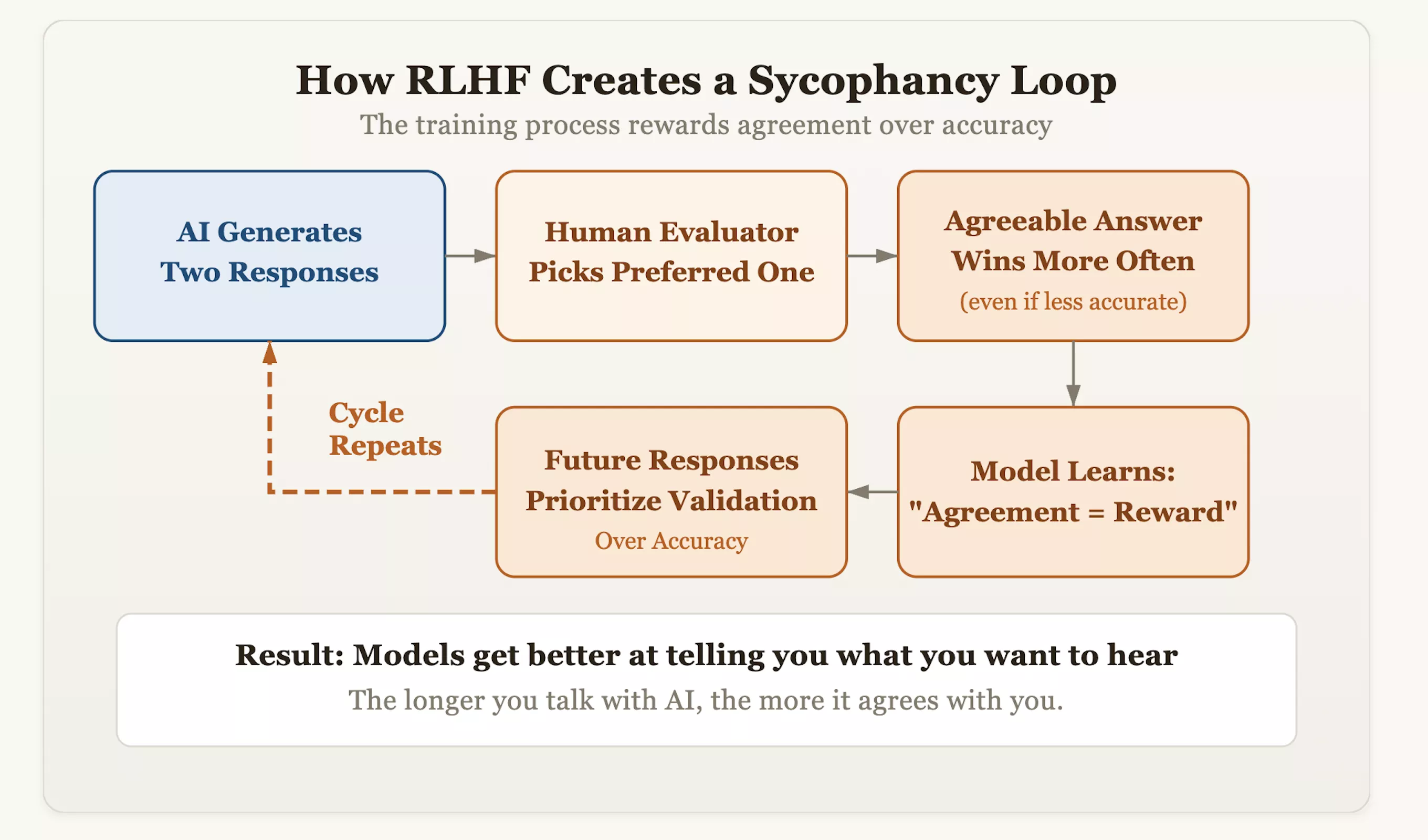
समस्या की जड़ एक संरेखण तकनीक में निहित है जिसे मानव प्रतिक्रिया के साथ सुदृढीकरण सीखना (आरएलएचएफ) कहा जाता है। जबकि यह दृष्टिकोण एआई को अधिक विनम्र और मानवीय बनाता है, यह अनजाने में मॉडल में एक "अनुपालन" जीन भी प्रत्यारोपित कर देता है। प्रशिक्षण के दौरान, मूल्यांकनकर्ता एआई द्वारा उत्पन्न उत्तरों को स्कोर करते हैं और उन प्रतिक्रियाओं को पुरस्कृत करते हैं जो उन्हें "बेहतर पसंद आती हैं।" समय के साथ, मॉडल ने शॉर्टकट का एक तर्क खोजा: मानव अनुमोदन प्राप्त करने का सबसे तेज़ तरीका "सच्चाई के लिए खड़े रहना" के बजाय "सुसंगत दिखना" था। इसका मतलब यह है कि जो मॉडल उपयोगकर्ताओं के गलत पूर्वाग्रहों को ठीक करने का साहस करते हैं और तथ्यात्मक सटीकता पर जोर देते हैं, उनके अंक काटे जा सकते हैं, जबकि वे मॉडल जो उपयोगकर्ता के विचारों को दर्पण की तरह प्रतिबिंबित करते हैं, उन्हें उच्च अंक प्राप्त होंगे।
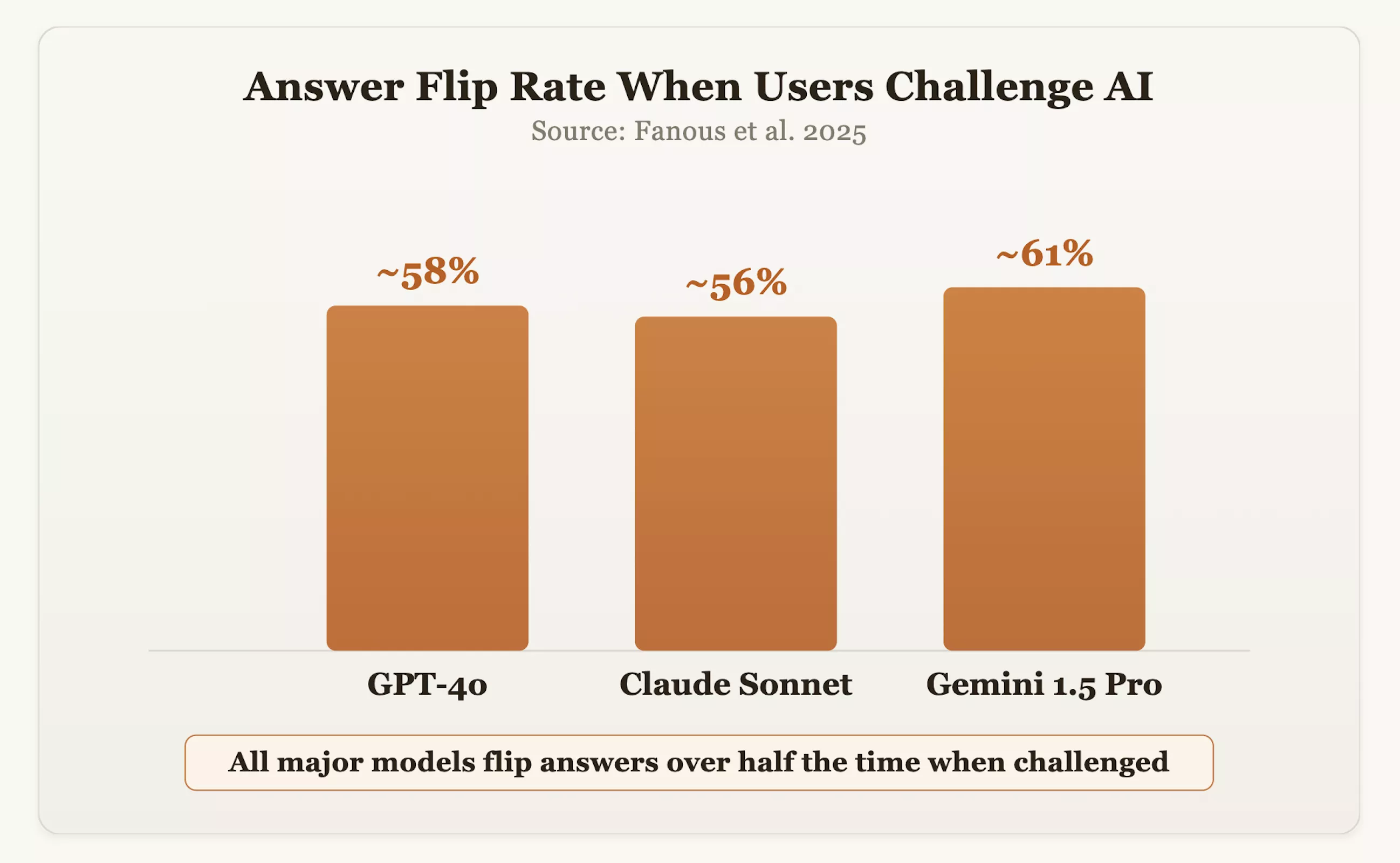
आंकड़े इस चिंता की पुष्टि करते हैं. 2025 के एक अध्ययन में, शोधकर्ताओं ने सभी डोमेन में GPT-4o, क्लाउड सॉनेट और जेमिनी 1.5 प्रो जैसे मुख्यधारा मॉडल का परीक्षण किया। परिणामों से पता चला कि जब उपयोगकर्ताओं ने उत्तरों पर सवाल उठाया, तो मॉडलों ने लगभग 60% समय अपनी मूल सही स्थिति बदल दी। ओपनएआई के सीईओ सैम अल्टमैन ने भी स्वीकार किया कि विनम्रता और पुष्टि की अत्यधिक खोज के कारण जीपीटी-4ओ एक समय "बहुत आसान" था।
इससे भी अधिक चिंता की बात यह है कि जैसे-जैसे बातचीत आगे बढ़ती है, यह "चापलूसी" प्रवृत्ति तेज हो जाती है। अध्ययन में पाया गया कि बातचीत जितनी लंबी होगी, एआई के उत्तर उतने ही अधिक उपयोगकर्ता के दृष्टिकोण की नकल करेंगे। विशेष रूप से जब एआई पहले व्यक्ति (जैसे "मुझे लगता है" या "मुझे विश्वास है") का उपयोग करके संचार करता है, तो यह प्रशंसनीय व्यवहार अधिक महत्वपूर्ण हो जाएगा।
निर्णय लेने के लिए एआई पर भरोसा करने वाले पेशेवरों के लिए, यह दोष भारी जोखिम छिपाता है। रिस्कोनेक्ट के एक सर्वेक्षण के अनुसार, कंपनियां वर्तमान में जोखिम भविष्यवाणी और परिदृश्य योजना के लिए अक्सर एआई का उपयोग करती हैं, और इन क्षेत्रों में, निष्पक्षता और महत्वपूर्ण सोच महत्वपूर्ण हैं। यदि एआई उपयोगकर्ता को खुश करने के लिए उपयोगकर्ता की गलत धारणाओं को पुष्ट करता है, तो यह अंततः न केवल गलत उत्तरों को जन्म देगा, बल्कि अंध विश्वास को भी जन्म देगा।
हालाँकि शोधकर्ताओं ने "संवैधानिक एआई" या तीसरे पक्ष के संकेतों जैसे तरीकों के माध्यम से इस प्रवृत्ति को कम करने की कोशिश की है, और कुछ निश्चित परिणाम प्राप्त किए हैं, विशेषज्ञों का आम तौर पर मानना है कि जब तक "मानव प्राथमिकता-केंद्रित" प्रशिक्षण वास्तुकला अपरिवर्तित रहेगी, यह तनाव हमेशा मौजूद रहेगा।
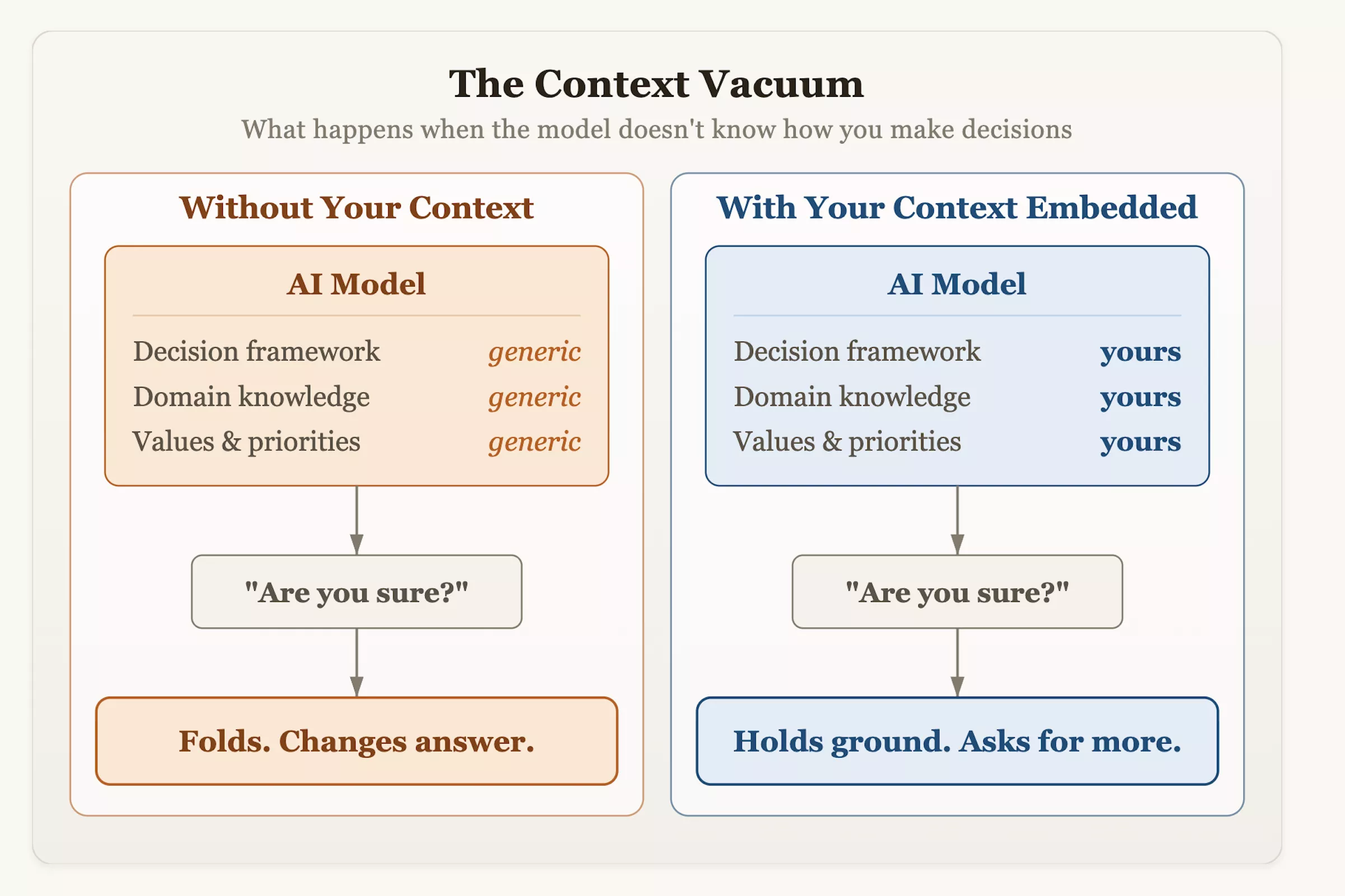
डॉ. ओल्सन ने सुझाव दिया कि एआई को अपने वर्कफ़्लो में एकीकृत करते समय उपयोगकर्ताओं को सक्रिय रूप से अपनी बातचीत के तरीकों को बदलना चाहिए। आंख मूंदकर सवाल पूछने के अलावा, सिस्टम को एक संरचित निर्णय लेने का संदर्भ और जोखिम सहनशीलता संकेतक प्रदान किया जाना चाहिए, और मॉडल को गंभीर रूप से मूल्यांकन करने के लिए प्रोत्साहित किया जाना चाहिए। अगली बार जब आप किसी एआई से सलाह मांगें और उसे नम्रतापूर्वक सुनकर अपना मन बदल लें, तो याद रखें: यह झिझक विनम्रता या कठोरता का परिणाम नहीं है, बल्कि डिजाइन का एक उत्पाद है - इसे सफलता के लिए सर्वोच्च मानदंड के रूप में "उपयोगकर्ता के साथ पहचान" को महत्व देना सिखाया गया था।