नील्सन के स्वामित्व वाली मेटाडेटा और सामग्री पहचान सेवा कंपनी ग्रेसनोट ने ओपनएआई के खिलाफ न्यूयॉर्क के दक्षिणी जिले के लिए अमेरिकी संघीय न्यायालय में मुकदमा दायर किया है, जिसमें आर्टिफिशियल इंटेलिजेंस कंपनी पर चैटजीपीटी जैसे वाणिज्यिक उत्पादों का समर्थन करने वाले बड़े भाषा मॉडल के प्रशिक्षण के लिए अपने मीडिया मेटाडेटा डेटाबेस और अद्वितीय डेटा एसोसिएशन ढांचे को बिना किसी प्राधिकरण और बिना किसी शुल्क का भुगतान किए बड़े पैमाने पर क्रॉल करने और उपयोग करने का आरोप लगाया गया है, जो गंभीर कॉपीराइट उल्लंघन है और इसके मुख्य व्यवसाय को खतरे में डाल रहा है।
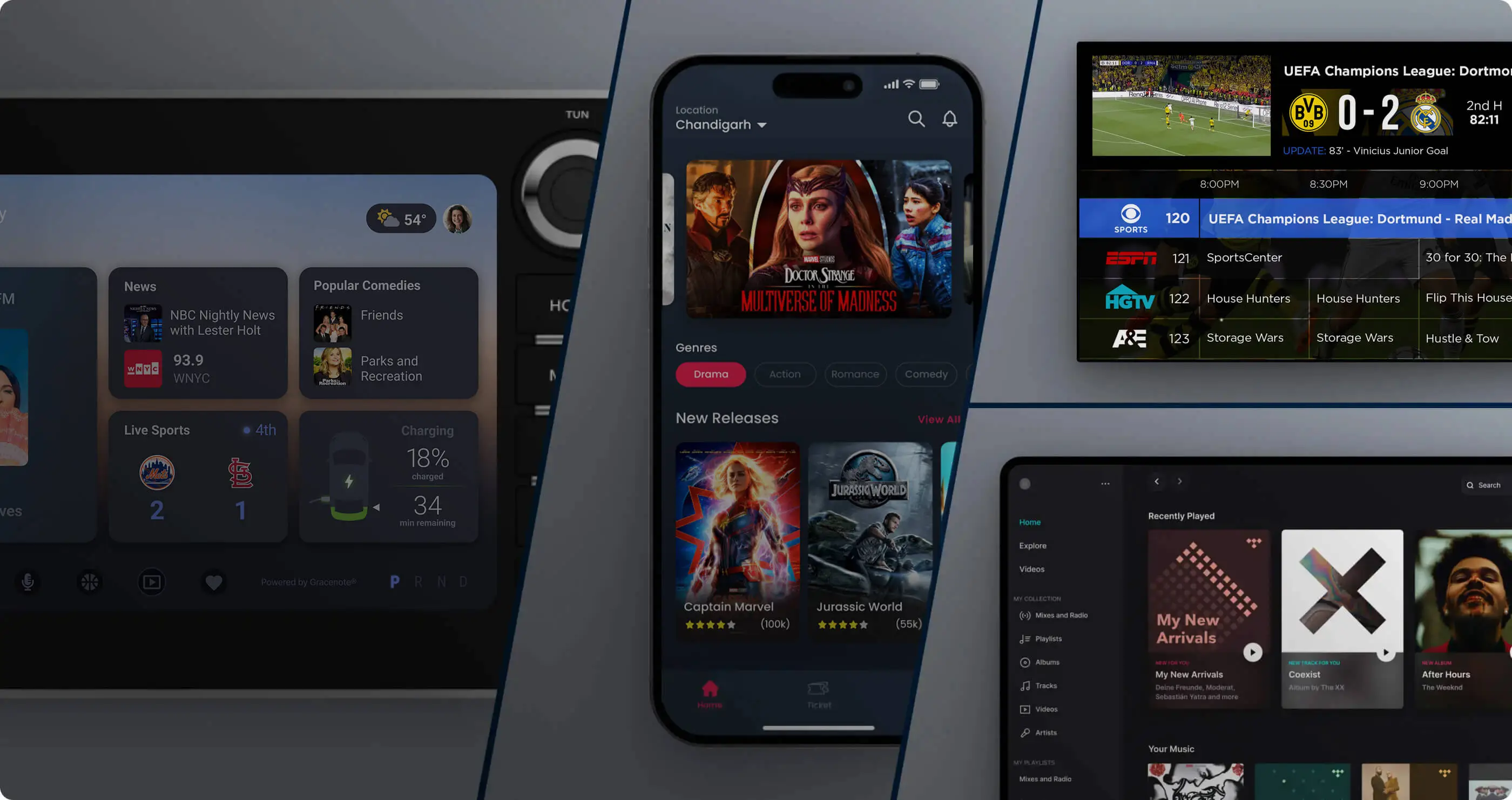
ग्रेसनोट ने शिकायत में कहा कि इसने दुनिया भर में फिल्म, टेलीविजन, संगीत और खेल सामग्री को मैन्युअल रूप से संपादित और एनोटेट करने के लिए वर्षों से सैकड़ों संपादकों पर भरोसा किया है, और एक "प्रोग्राम डेटाबेस" स्थापित किया है जिसमें प्रोग्राम परिचय, वीडियो फीचर विवरण, अद्वितीय सामग्री पहचानकर्ता और जटिल संबंध ग्राफ शामिल हैं, और अमेरिकी कॉपीराइट कार्यालय के साथ पंजीकरण पूरा कर लिया है। कंपनी का मानना है कि इस डेटाबेस में न केवल विशिष्ट पाठ्य सामग्री शामिल है, बल्कि विभिन्न कार्यों को वर्गीकृत, संबद्ध और व्यवस्थित करने के लिए एक मालिकाना संरचनात्मक डिज़ाइन भी शामिल है। यह "रिलेशनशिप फ्रेमवर्क" स्ट्रीमिंग मीडिया प्लेटफॉर्म और स्मार्ट टीवी निर्माताओं जैसे उद्यम ग्राहकों के लिए अपनी सेवाओं के लिए मूल्य का एक महत्वपूर्ण स्रोत है।
शिकायत में कहा गया है कि ओपनएआई ने उपरोक्त डेटा को बिना अनुमति के क्रॉल और आत्मसात कर लिया है, और जब उपयोगकर्ता चैटजीपीटी के माध्यम से प्रश्न पूछते हैं, तो यह एक विवरण आउटपुट करता है जो लगभग शब्दशः तरीके से ग्रेसनोट प्रोग्राम परिचय के समान या पूरी तरह से सुसंगत था। ग्रेसनोट द्वारा प्रदान किए गए उदाहरणों में शामिल है जब एक उपयोगकर्ता ने चैटजीपीटी से लोकप्रिय टीवी श्रृंखला गेम ऑफ थ्रोन्स का वर्णन करने के लिए कहा, और मॉडल ग्रेसनोट संपादकों द्वारा लिखे गए संस्करण के लगभग समान सामग्री के साथ आया। कंपनी ने यह भी कहा कि चैटजीपीटी के कई संस्करण अपने डेटाबेस में प्रोग्राम विवरणों के बड़े हिस्से को बहुत कम त्वरित शब्दों के साथ सुनाने में सक्षम थे, जो दर्शाता है कि प्रासंगिक पाठ और इसकी अंतर्निहित संगठनात्मक संरचना को सीधे कॉपी किया गया था और मॉडल में एम्बेड किया गया था।
ग्रेसनोट ने प्रस्तावित किया कि ओपनएआई के मेटाडेटा और रिलेशनल फ्रेमवर्क के अनधिकृत उपयोग ने न केवल कॉपीराइट पाठ और डेटाबेस संरचनाओं का उल्लंघन किया, बल्कि मीडिया सामग्री वितरकों और उपकरण निर्माताओं को "फ्री क्रॉल किए गए डेटा" के आधार पर वैकल्पिक मेटाडेटा सेवाओं के निर्माण की संभावना भी प्रदान की, जिससे ग्रेसनोट के समान उत्पादों की बाजार प्रतिस्पर्धात्मकता सीधे तौर पर कमजोर हो गई। शिकायत में चेतावनी दी गई है कि यदि इस तरह के व्यवहार को रोका और ठीक नहीं किया जा सकता है, तो स्मार्ट टीवी जैसे टर्मिनल निर्माता अपने स्वयं के मेटाडेटा प्लेटफॉर्म बनाने के लिए एआई मॉडल से "विपरीत रूप से प्राप्त" डेटा पर भरोसा कर सकते हैं जो बिना किसी लाइसेंस शुल्क का भुगतान किए ग्रेसनोट के साथ प्रतिस्पर्धा करते हैं।
दावों के संदर्भ में, ग्रेसनोट इस तथ्य पर निर्भर करता है कि इसका डेटाबेस अमेरिकी कॉपीराइट कार्यालय के साथ पंजीकृत किया गया है, और वास्तविक नुकसान के लिए मुआवजे की मांग करने के अलावा, यह चल रहे और बड़े पैमाने पर उल्लंघन के दावों से निपटने के लिए वैधानिक क्षति की भी मांग करता है। तथाकथित वैधानिक क्षति विशिष्ट प्रकार के कॉपीराइट उल्लंघन के लिए कानून द्वारा पूर्व निर्धारित एक निश्चित या सीमा राशि को संदर्भित करती है, जबकि वास्तविक क्षति का उपयोग उल्लंघन के कारण हुए वास्तविक आर्थिक नुकसान के लिए सही धारक को मुआवजा देने के लिए किया जाता है।
एक्सियोस के साथ एक साक्षात्कार के जवाब में, ओपनएआई के प्रवक्ता ने कहा कि इसके मॉडल "नवाचार को सक्षम करते हैं" और "सार्वजनिक रूप से उपलब्ध डेटा" पर प्रशिक्षित होते हैं और "उचित उपयोग" द्वारा समर्थित होते हैं। ओपनएआई समेत कई एआई कंपनियों ने लगातार तर्क दिया है कि सार्वजनिक इंटरनेट सामग्री को क्रॉल करके प्रशिक्षण मॉडल वर्तमान अमेरिकी कॉपीराइट कानून के तहत उचित उपयोग के निर्धारण के अनुरूप है, इस आधार पर कि ये डेटा मॉडल द्वारा परिवर्तित होने के बाद उपयोगकर्ताओं को नई और उपयोगी सेवाएं और जानकारी प्रदान कर सकते हैं।
ग्रेसनोट का मुकदमा ध्यान आकर्षित करने का एक और कारण यह है कि कंपनी हमेशा एआई कंपनियों के साथ सहयोग के लिए खुली रही है और सैमसंग, गूगल और अन्य कंपनियों के साथ कई एआई-संबंधित डेटा लाइसेंसिंग समझौतों पर पहुंची है। ग्रेसनोट ने शिकायत में कहा कि उसने लाइसेंसिंग मामलों पर चर्चा करने के लिए कई बार ओपनएआई से संपर्क किया, लेकिन "बार-बार खारिज कर दिया गया या लंबे समय तक नजरअंदाज किया गया" और इसलिए उसे अपने अधिकारों और हितों की रक्षा के लिए मुकदमेबाजी का सहारा लेना पड़ा। कंपनी के सीईओ जेरेड ग्रुस्ड ने एक बयान में इस बात पर जोर दिया कि "एआई के विकास का समर्थन करना और चोरी का विरोध करना असंगत नहीं है। वे उद्योग के सतत विकास का एकमात्र मार्ग हैं," उन्होंने कहा कि मुकदमे का उद्देश्य इस भविष्य की रक्षा करना है।
कानूनी पेशेवरों का मानना है कि मीडिया और सूचना कंपनियों और एआई कंपनियों के बीच कई कॉपीराइट विवादों के अदालती फैसलों की प्रतीक्षा में होने के कारण, यह मामला न्यायाधीशों के लिए यह जांचने के लिए एक महत्वपूर्ण संदर्भ बनने की संभावना है कि क्या "गैर-पारंपरिक कार्य" जैसे डेटाबेस संरचनाएं और मेटाडेटा एसोसिएशन मानचित्र कॉपीराइट सुरक्षा प्राप्त कर सकते हैं और "बड़े मॉडलों के उचित उपयोग की सीमा" कैसे निर्धारित की जाए। ग्रेसनोट ने अपनी शिकायत में इस बात पर जोर दिया कि ओपनएआई द्वारा उत्पादित अधिकांश सामग्री उस मेटाडेटा के "लगभग समान" है जो उसने अपने ग्राहकों को लाइसेंस दिया है। इसलिए, यह नई जानकारी प्राप्त नहीं करता है, बल्कि मौजूदा सामग्री की एक बड़ी प्रतिलिपि है। यह विवाद के प्रमुख बिंदुओं में से एक बन जाएगा जो इस मामले को अन्य एआई कॉपीराइट मामलों से अलग करता है।